Improving transfer speeds for ZFS send/receive in a local network
I recently had to send a couple of ZFS file systems from one server to another, both running Ubuntu Linux 16.04. Since both servers were in the same trusted local network, there was no need for encryption. As various other websites will tell you, the fastest way to transfer data over a local network is with the netcat (nc) utility. Since nc doesn’t encrypt anything (like SSH would) and only acts as a simple pass-through this should indeed give best performance.
On the receiving end (the backup machine), I ran
nc -l 8000 | \ mbuffer -q -s 128k -m 1G | \ pv -rtab | \ sudo zfs receive -vF backups/home
Here the -l option to nc tells it to listen on port 8000. In addition to nc I also added mbuffer1 to act as a buffering layer. The -s option sets the block size of the buffer, given that ZFS’ default block size is 128 kB, I chose the same size. The -m option sets the buffer size. The 1 GB I specified is probably a bit big, but since both machines had ample RAM, this was of no concern. The pv tool displays the progress of data transfer. The -r option shows the rate of data transfer, the -t option shows the transfer time, the -a option shows the average transfer rate, and the -b option shows the total bytes sent.
On the sending side, I started the following to send an incremental series of snapshots:
sudo zfs send -I storage/home@2016-06-01_monthly storage/home@2016-09-01_monthly | \ mbuffer -q -s 128k -m 1G | \ pv -b | \ nc 192.168.20.3 8000
The reason for explicitly specifying the ip address and not the host name of the receiving server is because, in addition to normal gigabit network connections via a switch, both servers also have a direct 10Gb/s link (two Mellanox ConnectX EN PCIe 2.0 cards). I wanted to make sure that that connection was used for the transfer.
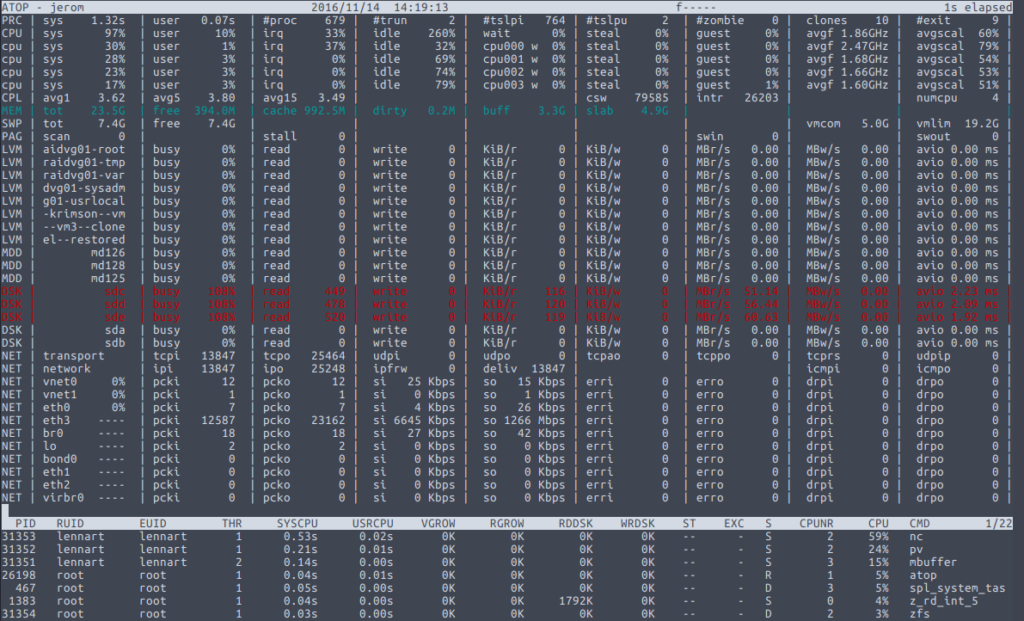
I then started atop to observe how the transfer proceeded. This was somewhat disappointing, because transfer rates were stuck just above Gbit speeds, roughly between 990 Mbps and 1200 Mbps. However, on the sending end, CPU usage of nc was close to or at 100%. Since this is a rather low-spec machine with an old dual core Intel Core i3 2100 CPU, this may not have been too surprising. A closer look at atop‘s output showed that a lot of CPU time was actually spent servicing irqs. So I needed to find ways to reduce the number of interrupts sent by the network card.
Because I know from previous experience that optimising TCP/IP parameters can have a dramatic effect on transfer rates and CPU usage, I decided to see what I could optimise on this setup. The first thing that comes to mind is to increase the MTU of both network cards. The default is 1500, so I set it to 9000 on both cards:
ip link set dev eth3 mtu 9000
This increased transfer rates to roughly 1200 to 1400 Mbps and reduced the CPU usage of nc a bit.
Next, I looked at the transmit and receive buffers of the network cards:
$ ethtool -g eth3 Ring parameters for eth3: Pre-set maximums: RX: 8192 RX Mini: 0 RX Jumbo: 0 TX: 8192 Current hardware settings: RX: 1024 RX Mini: 0 RX Jumbo: 0 TX: 512
Increasing these buffers should also reduce the number of interrupts:
$ sudo ethtool -G eth3 rx 2048 tx 2048 $ ethtool -g eth3 Ring parameters for eth3: Pre-set maximums: RX: 8192 RX Mini: 0 RX Jumbo: 0 TX: 8192 Current hardware settings: RX: 2048 RX Mini: 0 RX Jumbo: 0 TX: 2048
This led to in increase in transfer rate to approximately 1800 – 2500 Mbps according to atop and the CPU usage of nc now hovered between 30% and 91%. Moreover, atop showed me that by this time, the three disks comprising the RAIDZ1 volume on the sending server were the bottleneck. The disks spent all their time reading the data, so no point in optimising the transfer rate even further.
By this time, the output of pv on the receiving server showed me transfer peaks of about 240 MB/s, with an average transfer rate of 173 MB/s after 38 minutes of transfer time and 390 GiB transferred.
So the bottom line is: there is always a bottleneck, however, some bottlenecks are more easily overcome than others. With a simple change of two parameters I roughly doubled the transfer rate of this transfer of several TB of data.
Footnotes
- One thing I probably should have tried in hindsight, is to remove
ncfrom the equation altogether and letmbufferhandle the transfer (see also here).
No Comments